UE5.0 AsyncCompute异步计算优化简易教程
现代图形API(DX12/Vulkan)以队列为单位提交录制好的Command Buffer, 通常GPU上至少有三种独立的队列类型:Graphics(gfx), Compute, Copy。
提交到队列中的命令并不保证严格的执行先后顺序,但Pass之间总是需要插入Barrier做好同步的。而Pass本身用到的SM Warp有限,因此,在Pass执行过程中,通常会出现Main Graphics队列忙碌,但Warp使用量较低(SM Occupancy低)的情况。
因此,找到出现这种情况的区域,并插入对应的Async Compute Pass,能让SM Occupancy大幅度提升,同时也减少了Main Graphics Queue的任务数量,提升帧率。
以ShadowDepth绘制Pass为例,在Main Graphics Queue绘制Shadow Depth前,插入了Async SSAO的计算任务,截帧如下:
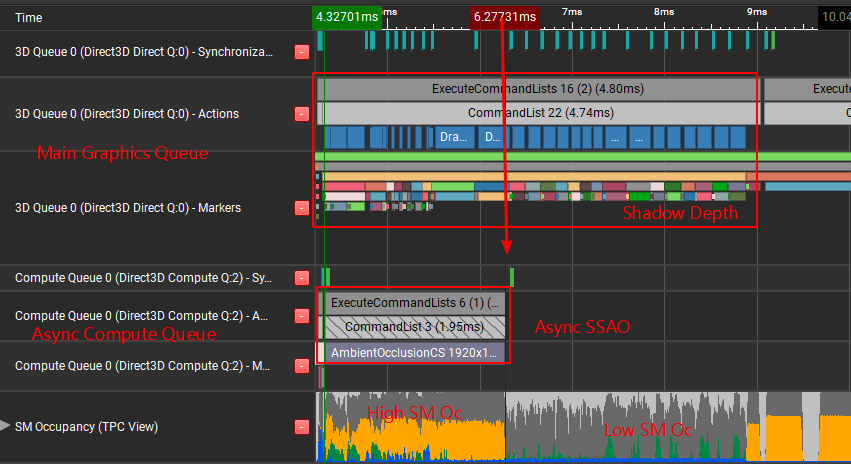
ShadowDepth Pass绘制过程中SM Oc非常的低,插入Async SSAO后,可以在异步计算队列里利用这部分 Unused Warp,同时不会阻塞Main Graphics Queue的任务,四舍五入等于白嫖一份SSAO的计算时间。
当然不是任何时候插入Async Compute都有优化效果的,每次提交到异步队列中的Command buffer都需要和主队列做好Sync同步,随意插入Async compute, 插入的Semaphore可能需要Main Graphics等待一段时间。
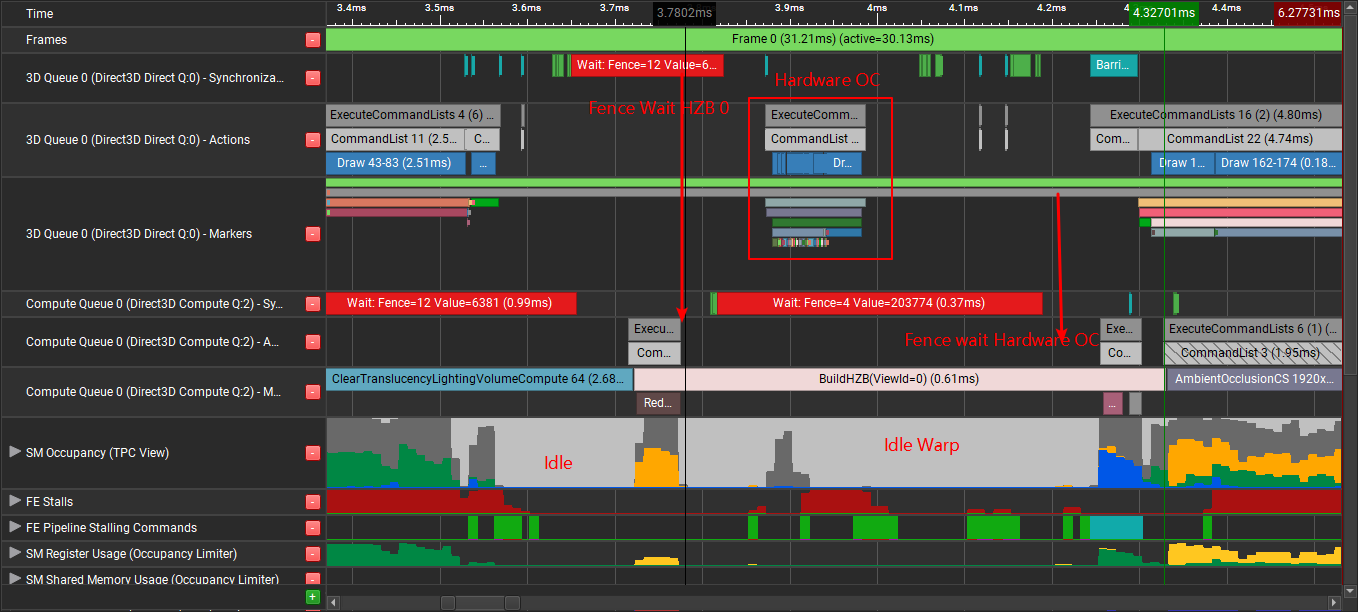
如下所示,异步HZB Build放到了硬件Occlusion Culling之前,由于硬件Culling需要DepthStencil Buffer(Depth ReadOnly Stencil Write),HZB Build的第一次build需要原始的Depth Buffer SRV,(我个人感觉不应该在这里插入semaphore)RDG会插入一个Depth Resource的Barrier,导致MainGraphics的硬件Culling需要等待HZB第一次Build结束后才执行,同时也导致GPU出现一大段Idle warp区域(灰白色):
UE4中如何插入Async Compute
RHI中创建时就已经根据硬件信息准备好异步队列对应的Commandlist了,透过静态方法FRHICommandListExecutor::GetImmediateAsyncComputeCommandList()暴露出来。UE 4.27下纯RHI调用方法如下:
// Main graphics command list.
FRHICommandListImmediate& RHICmdList;
// UAV Resource queue owenership transfer.
auto* UAVTransition = RHICreateTransition(ERHIPipeline::Graphics, ERHIPipeline::AsyncCompute, ...);
auto* SRVTransition = RHICreateTransition(ERHIPipeline::AsyncCompute, ERHIPipeline::Graphics,....);
// Start MainGraphics --> AsyncCompute
RHICmdList.BeginTransition(UAVTransition);
auto& RHICmdListComputeImmediate = FRHICommandListExecutor::GetImmediateAsyncComputeCommandList();
{
// Wait when MainGraphics --> AsyncCompute transition finish.
RHICmdListComputeImmediate.EndTransition(UAVTransition);
// Do some async compute here, and write resource to uav.
DispatchComputeShader(RHICmdListComputeImmediate, ...);
// Async compute finish..............
// Start AsyncCompute --> MainGraphics
RHICmdListComputeImmediate.BeginTransition(SRVTransition);
}
FRHIAsyncComputeCommandListImmediate::ImmediateDispatch(RHICmdListComputeImmediate);
// Do other graphics pass.
// When need sync
AddPass(GraphBuilder, [this](FRHICommandList& RHICmdList)
{
//Main Graphics Wait AsyncCompute --> MainGraphics
RHICmdList.EndTransition(SRVTransition);
});
纯RHI的做法可以自由安排同步时机,可以用来做一些跨帧异步计算的操作,比较灵活。
在RDG中调用Async Compute方法仅需在Add Pass时增加标记ERDGPassFlags::AsyncCompute.

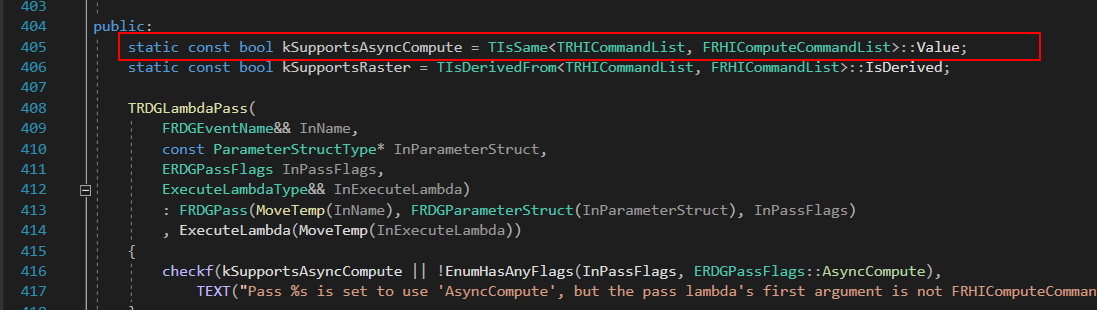
如果想手动填充Pass Lambda,需保证AddPass的类型参数为(FRHIComputeCommandList& RHICmdList):

RDG内部做了类型萃取,编译时仅该类型的Lambda Pass才会分发到Async Compute,否则覆写Flag为Main Graphics的Compute.
RDG会自动处理资源的转换,但有时候插入的Semaphore可能不太理想,因此需要Nsight仔细检查Main Graphics每一处的Sync,减少阻塞。
UE4 Async Compute转换麻烦的地方
#1. 不少Pass Parameter的组织方式还是原来的LAYOUT_FIELD方式,SetParameter函数也是用的FRHICommandList,而异步计算提供的CommandList类型为FRHIComputeCommandList,两者的继承关系为:

因此没有办法简单复用原有的代码,而UE的效果一般变体都很多,Pass的复杂度也很高,改成Async Compute工作量很大。
#2. UE4 不是每个效果都提供了Compute Shader版本,如果要改成Async Compute,在考虑原有效果不变的情况下,要充分利用Shared Memory加速,写出一个效率高的CS还是挑战性很高的。
换言之,这就是个纯粹的搬砖活。
如何抓帧Profile Async Compute
首先我们需要打包游戏,一般Development包即可,Shipping包的一些Marker信息可能会丢失不便Profile。
一般使用两个软件抓帧:PIX和Nsight.
PIX抓帧比较简单,就正常用Pix启动游戏然后按下printscreen按钮即可。
然后我们得到一个wpix捕获。
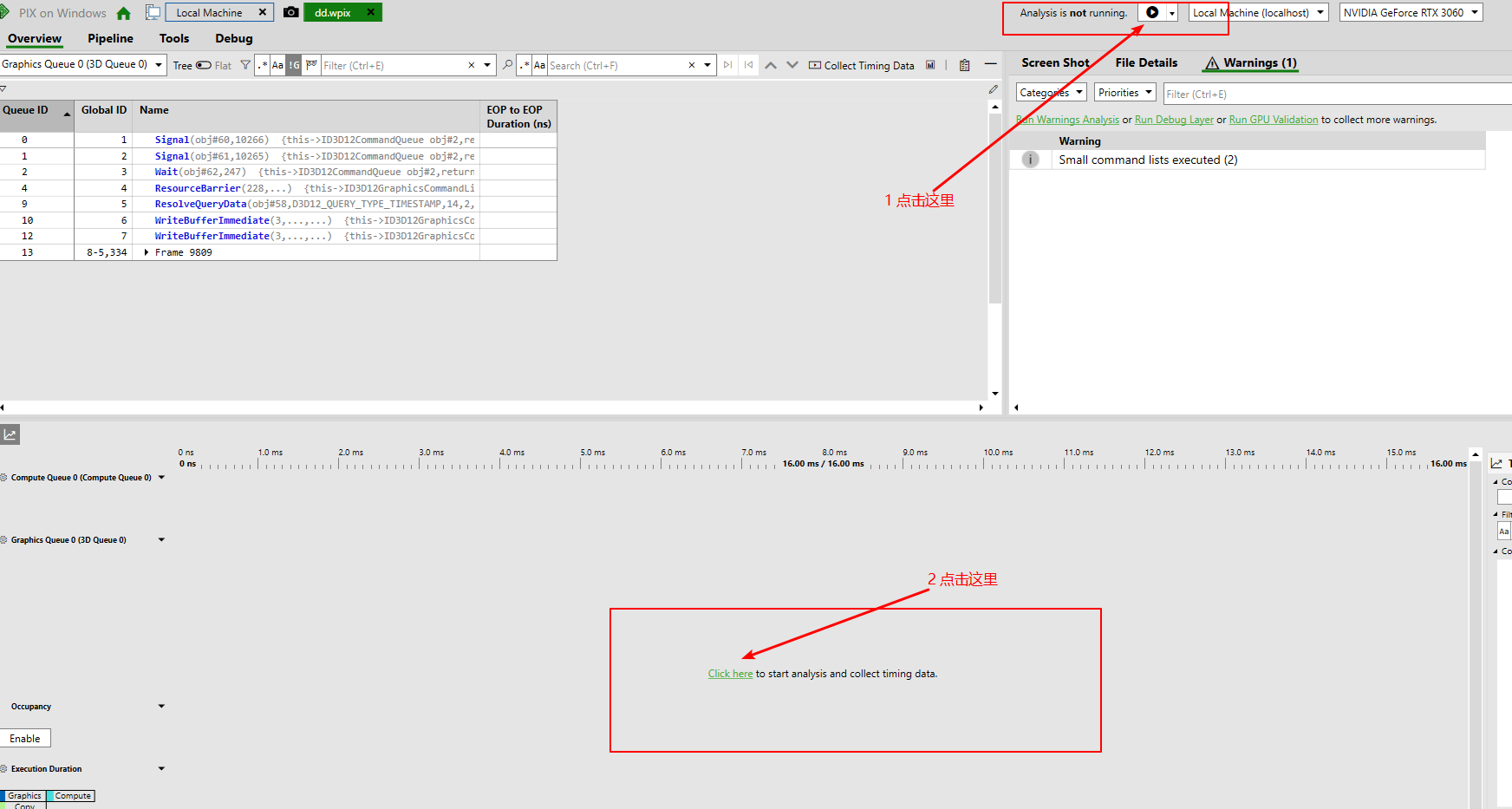
一定要按照如图顺序启动,不然UI会变乱。
然后我们就能得到一份运行柱状图了:
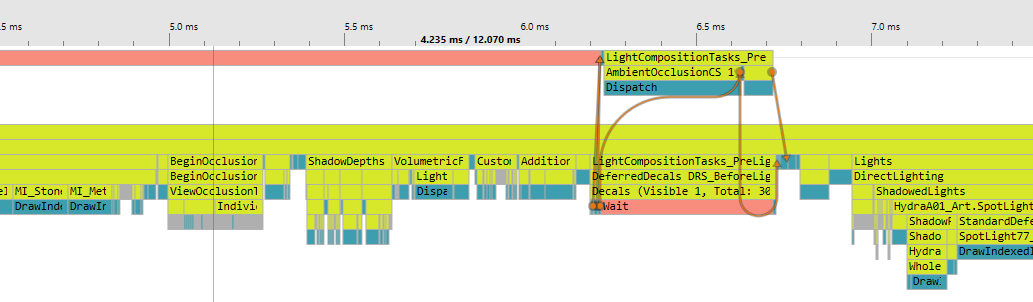
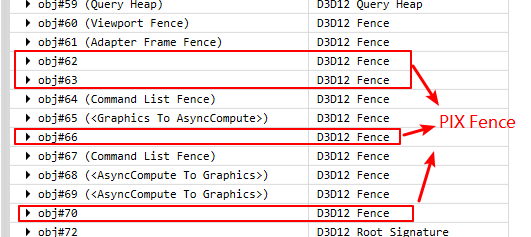
注意,在Graphics Queue0中的Wait有可能是PIX自己插进来的Fence,可以点击那个Wait等待的Fence Object,如果没有DebugName,则是PIX创建的。(UE4 DX12 RHI所有Fence创建都有DebugName).
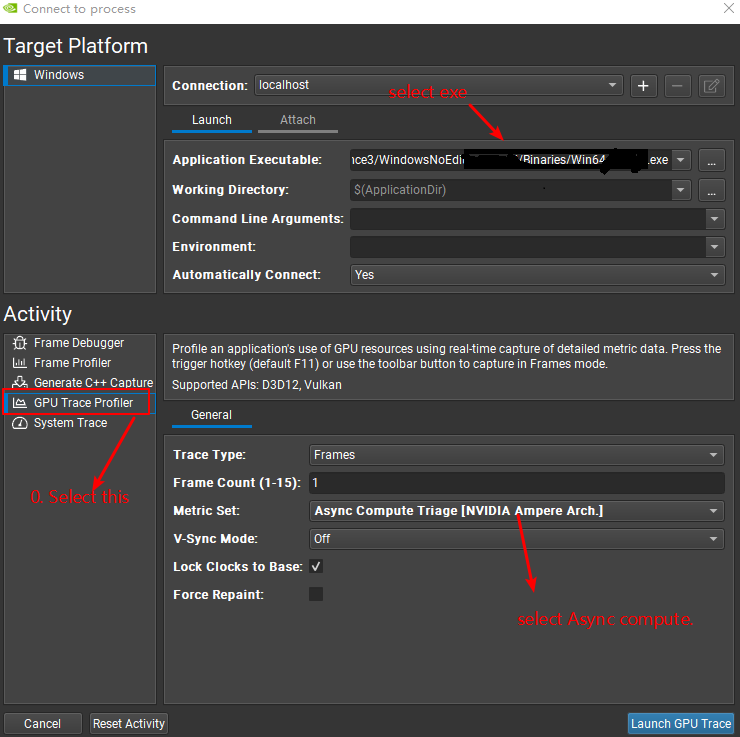
Nsight捕获步骤如下:
Nisght捕获的信息较全,按我的经验来,最重要的部分如下三个:
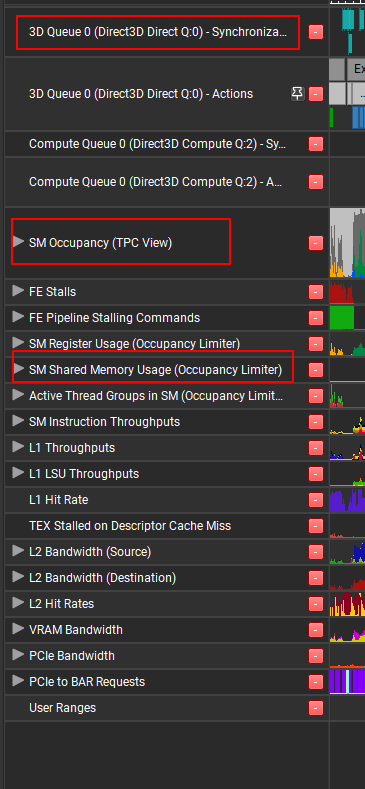
第一个是3D Queue的Sync,通常来说,Async Compute队列从来不应该让3D queue等待,如果出现了Sync部分,就需要改调度代码了。
第二个是SM Occupancy, 指示了Idle Warp和Unused Warp的数目,理想情况下越高越好,如果有些区域出现很多空闲的Warp,考虑插入Async Compute.

第三个是 SM Shared memory使用率,片上缓存很珍贵,如果CS耗尽Shared Memory,能同时调度的线程数就会下降,也会减低执行速度。
其余的数据,如L1/L2 Cache Hit, PCIe load, 只能当作一个参考,很多时候算法就是会导致大量的Cache Miss, 并无太大优化参考价值。