使用Quad指令加速3x3Filter
做图像处理时经常要做3x3小范围的滤波,这种情况下,使用LDS + GroupMemoryBarrierWithGroupSync均摊的优化不一定会有收益。
究其原因:3x3范围内,本身的Texture Cache命中率就很高,不会出现TexelLoad的瓶颈;其次,Shader编译器在O3及以上的优化下,会做指令重排来最大化Hide Latency,而我们加入的GroupMemoryBarrierWithGroupSync指令则打破这一优化,最终编译出来的指令额外多了几处s_wait,最终执行性能不升反降。
但借助SM6.0的Quad指令,可以写出所有情况下均为正收益的3x3滤波优化。
考察像素着色器情况:
像素着色器2x2为一个Quad执行,它的空间分布如下:
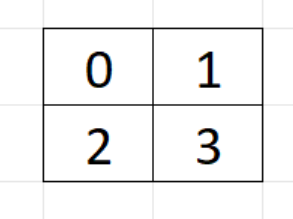
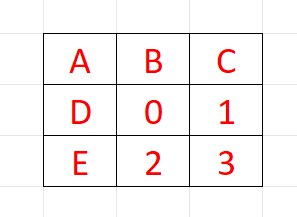
假设我们需要对像素0做3x3的滤波,它要处理的像素空间分布如下,一共九次计算(红色代表本线程的计算):
SM6.0的Quad指令为我们提供了访问同一组Quad内其它Lane内容的能力。
比如:
- 在像素0处使用QuadReadAcrossX即可得到像素1处的值;在像素1处使用则可得到0处的值。
- 在像素0处使用QuadReadAcrossY可以得到像素2处的值;在像素2处使用则可得到0处的值。
- 在像素0处使用QuadReadAcrossDiagonal得到像素3处的值;在像素3处使用则可得到0处的值。
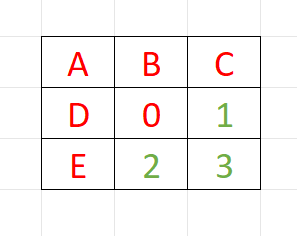
因此,如果每个像素都计算了它本身位置的结果,那么结果可以直接通过Quad指令共享给其它线程。
此时,像素0处的计算分布如下(绿色代表通过Quad指令得到的共享结果):
更进一步,若Quad内每个像素都按照如下的模式采样,那么每个像素需要计算4次:
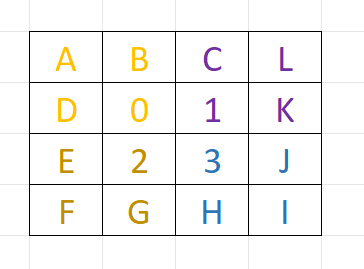
像素0处的3x3Filter计算,E处可以直接通过D处的QuadReadAcrossY得到,同理,C处可以通过B处的QuadReadAcrossX得到;像素0本身仅需计算A, B, D, 0这4个位置的结果即可。
在计算着色器中,我们还需要对线程组做Quad重映射,得到类似像素着色器类似的调度分布。
// 8x8 Output:
// 00 01 08 09 10 11 18 19
// 02 03 0a 0b 12 13 1a 1b
// 04 05 0c 0d 14 15 1c 1d
// 06 07 0e 0f 16 17 1e 1f
// 20 21 28 29 30 31 38 39
// 22 23 2a 2b 32 33 3a 3b
// 24 25 2c 2d 34 35 3c 3d
// 26 27 2e 2f 36 37 3e 3f
// 8x8 情况
uint2 remap8x8(uint tid)
{
return uint2((((tid >> 2) & 0x7) & 0xFFFE) | (tid & 0x1),
((tid >> 1) & 0x3) | (((tid >> 3) & 0x7) & 0xFFFC));
}
[numthreads(64, 1, 1)]
void blurShadowMask(
uint2 workGroupId : SV_GroupID, uint localThreadIndex : SV_GroupIndex)
{
int2 dispatchThreadId = int2(workGroupId * 8 + remap8x8(localThreadIndex));
}
// 通常情况
uint2 ZOrder2D(uint Index, const uint SizeLog2)
{
uint2 Coord = 0;
for (uint i = 0; i < SizeLog2; i++)
{
Coord.x |= ((Index >> (2 * i + 0)) & 0x1) << i;
Coord.y |= ((Index >> (2 * i + 1)) & 0x1) << i;
}
return Coord;
}
[numthreads(TILE_SIZE, TILE_SIZE, 1)]
void mainCS(uint2 workGroupId : SV_GroupID, uint localThreadIndex : SV_GroupIndex)
{
uint2 dispatchThreadId = workGroupId * uint2(TILE_SIZE, TILE_SIZE));
dispatchThreadId += ZOrder2D(localThreadIndex, log2(TILE_SIZE);
}
最终的计算代码如下所示:
static const int2 k3x3QuadSampleSigned[4] =
{
int2(-1, -1),
int2(+1, -1),
int2(-1, +1),
int2(+1, +1),
};
static const int2 k3x3QuadSampleOffset[4] =
{
int2(0, 0), // Central
int2(1, 1),
int2(0, 1),
int2(1, 0),
};
// Example usage:
uint quadIndex = WaveGetLaneIndex() % 4;
float shadowMask[9];
[unroll(4)]
for (int i = 0; i < 4; i ++)
{
int2 samplePos = workPos +
k3x3QuadSampleOffset[i] * k3x3QuadSampleSigned[quadIndex];
samplePos = clamp(samplePos, 0, pushConsts.dim - 1);
shadowMask[i] = shadowMaskTexture[samplePos];
}
shadowMask[4] = QuadReadAcrossX(shadowMask[0]);
shadowMask[5] = QuadReadAcrossY(shadowMask[0]);
shadowMask[6] = QuadReadAcrossDiagonal(shadowMask[0]);
shadowMask[7] = QuadReadAcrossX(shadowMask[2]);
shadowMask[8] = QuadReadAcrossY(shadowMask[3]);
float shadowMaskSum = 0.0;
[unroll(9)]
for (int i = 0; i < 9; i ++)
{
shadowMaskSum += shadowMask[i];
}