MyNanite: 从零开始实现Nanite风格网格渲染器
虚幻引擎5里最吸引人的新特性莫过于Nanite。它可以自动的生成和无缝切换网格LOD,处理海量三角形并且让游戏保持一个较高的帧率。
最近一个月,我在引擎中实现了Nanite中的大部分特性,包括无缝的DAG Cluster LOD切换,两次HZB剔除,基于MeshShader的Visibility流程等。一些用处较小的特性(软光栅化)、一些和引擎其他功能耦合比较重的特性(IO和压缩)则跳过。而Nanite中的Material Passes,则被替换成更加现代化的、基于Bindless的实现。本文介绍了实现过程中遇到的一些主要技术细节。
最终视频:
https://www.bilibili.com/video/BV19THMedEuN
网格预处理
与新出的Mesh Shader管线的渲染流程相同,Nanite将临近的128个三角形组织成Cluster(或者称为Meshlet),每个网格都切割为多个Cluster。
LOD在Cluster Group级别上构建,Nanite描述了一种名为DAG Cluster Group LOD的层次结构,具体细节请查看:
https://www.youtube.com/watch?v=eviSykqSUUw
SylvesterHesp和jglrxavpok分别有一篇很棒的文章讲述了DAG Cluster Group LOD的构建流程。
https://blog.traverseresearch.nl/creating-a-directed-acyclic-graph-from-a-mesh-1329e57286e5
https://jglrxavpok.github.io/2024/01/19/recreating-nanite-lod-generation.html
本文的DAG Cluster Group LOD处理流程在jglrxavpok提到的流程基础上修改而来:
Cluster(Meshlet)划分、网格简化使用MeshOptimizer库,Cluster Group划分使用Metis库。
需要注意的是:网格简化时,输入的三角形列表要求拓扑连续,否则网格无法继续简化下去。
网格的三角形一般拓扑连续,但某些特殊的原因下(UV镜像,美术要卡硬边法线等),要分裂出额外的顶点,分裂出来的顶点会卡住MeshOptimizer的网格简化,导致分裂边附近的三角形将无法继续简化下去。
这种情况属于正常现象。
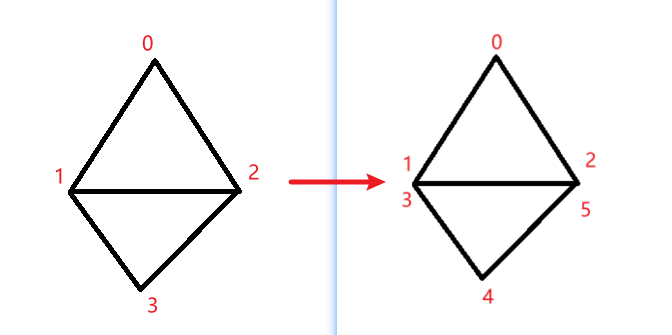
还有一种在Blender中被称为Loose Geometry的网格,在编辑模式中拖拽其中一个三角形,可以看到它根本和其他三角形无任何链接关系。(下图左侧为Loose Geometry,右侧为修复后的网格)

MeshOptimizer的网格简化对这种网格无能为力,不过修复起来也很快,仅需在编辑模式下选中所有的Loose Geometry,然后在网格级别让它们按照距离做融合即可。
构建DAG Cluster Group LOD的几大步骤:
- 使用meshoptimizer,按每128个三角形一个Cluster的做法,将原始网格切割为N个Cluster。
- 使用Metis将相邻的2 - 4个Cluster划分为一个Cluster Group。
- 合并Cluster Group里面的所有Cluster的三角形,使用meshoptimizer简化合并得到的网格。(简化过程中锁住边界,简化率为50%的三角形)
- 使用meshoptimizer,按每128个三角形一个Cluster的做法,将简化后的网格切割为N/2个Cluster,若此时的Cluster数目 > 2,跳到第二步。
第二步中需要到对Cluster列表构建空间上的临接关系图表:
以每个Cluster作为图里的一个顶点,图里的边则是两个相邻Cluster之间三角形连接边(可能存在多条边)。
如下图所示,Cluster #0 与 Cluster #1 临接,它们之间的连接边(红色三角形边)有多个。
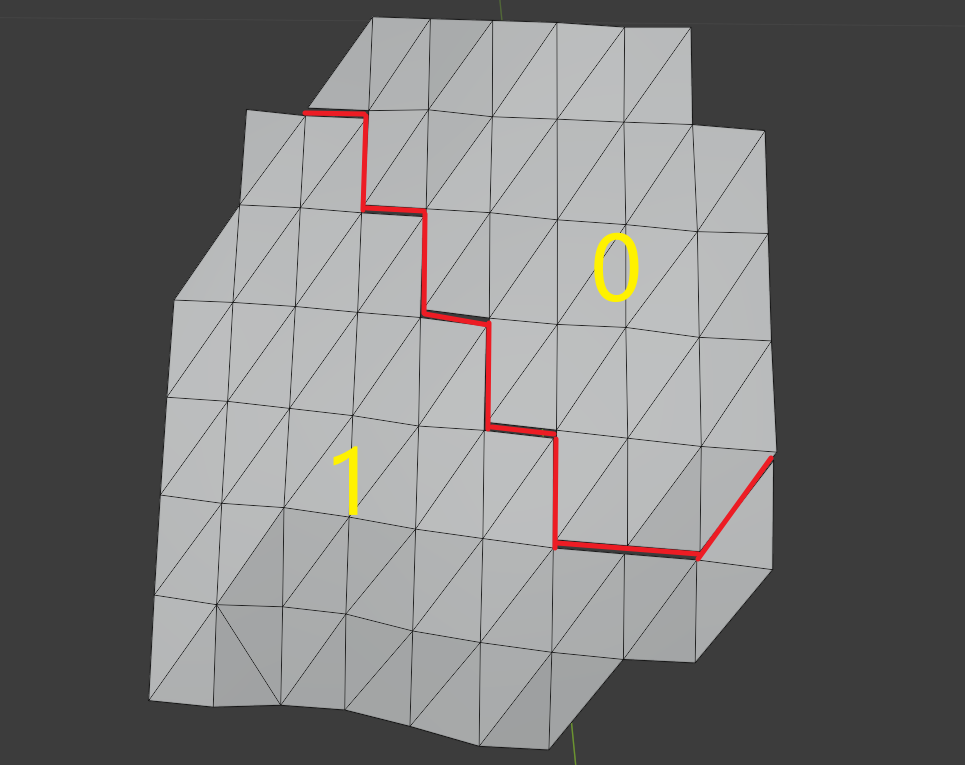
关键点在于找到每条三角形边周围有哪些Meshlet(Vert),每个Meshlet(Vert)拥有哪些边,可以用两个Map表示,构建伪代码如下:
map<edge, set<meshlet>> edge2meshlets;
map<meshlet, set<edge>> meshlet2edges;
for (meshlet : meshlets)
{
for (triangle : meshlet.triangles)
{
for (triangle_edge : triangle.edges)
{
uint v0 = hash_pos(triangle_edge.pos[0]);
uint v1 = hash_pos(triangle_edge.pos[1]);
// Edge为无向边,与顶点顺序无关,这样才能作为两个三角形的共享边
edge.p0 = min(v0, v1);
edge.p1 = max(v0, v1);
edge2meshlets[edge].insert(meshlet);
meshlet2edges[meshletIndex].insert(edge);
}
}
}
接下来将其转化为Metis要求的xadj和adjncy数组格式:
// xadj和adjncy的具体含义:
for (uint vert_a = 0; vert_a < vert_count; vert_a ++) // vert is meshlet
{
for (uint adjVert = xadj[vert_a]; adjVert < xadj[vert_a + 1]; adjVert++)
{
uint vert_b = adjncy[adjVert];
// Now get edge: (vert_a, vert_b)
}
}
// 构建xadj和adjncy
vector<uint> adjncy;
vector<uint> xadj;
for (meshlet : meshlets)
{
offset = adjncy.size();
xadj.push_back(offset); // 新顶点
for (edge : meshlet2edges[meshlet]) // 遍历meshlet里的所有边
{
for (adjMeshlet : edge2meshlets[edge])
{
if(adjMeshlet != meshlet) // 连接到其他顶点
{
if (not found adjMeshlet between adjncy[offset] and adjncy.end)
{
adjncy.add(adjMeshlet);
}
}
}
}
}
xadj.push_back(adjncy.size()); // 结束边界
此时即可调用METIS_PartGraphKway函数做分组划分了。
在第三步中,网格时使用meshopt_SimplifyLockBorder标记让网格简化过程中保留边界。
使用meshopt_SimplifyErrorAbsolute标记确保网格的简化误差在世界空间内,target_error需要乘上meshopt_simplifyScale的结果转换到世界空间。(每次调用meshopt_simplify后,默认得到是相对于上一个层级网格的相对误差,如果连续生成多级LOD,那么还要小心处理它们的单位转换,直接使用绝对坐标误差标记可以省掉这个繁琐的转换问题。)
LOD选择
meshopt_simplify使用类似Quadric Error Metrics简化算法,得到的Error大致能代表简化后的顶点与原表面的距离。
将以Cluster Group网格中心为原点,Error为半径的误差小球投影到屏幕空间上,若其半径小于一个像素,此时可以认为切换为当前LOD是无损的。
Nanite还为每个Cluster Group存储了其父节点的Error(Parent Error),将Parent Error小球也投影到屏幕上,与ClusterGroup本身的Error一起搭配,即可唯一确定应该使用哪个级别LOD。

我不太清除Nanite的ParentError/ClusterError投影方式是否有做啥特殊处理,用刚刚描述的做法,是无法确保ParentError永远大于ClusterError。
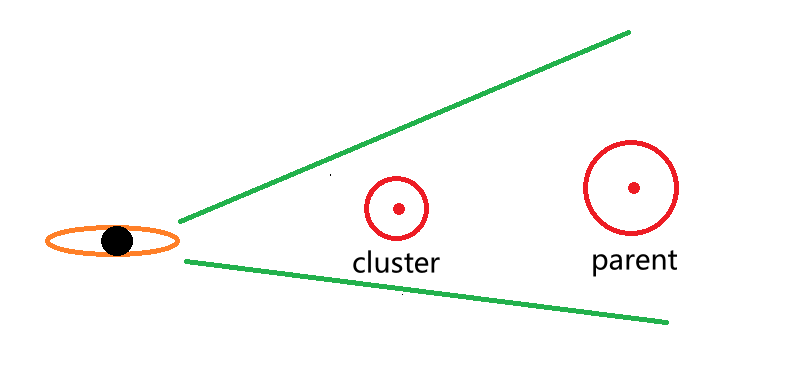
如图所示,parent因为是多个Cluster集合而成,所以parent网格中心可能位于某个Cluster的网格中心之后,在近大远小的原则下,如果parent的error半径没有增长太多,很有可能出现projected parent error < projected cluster error的情况。
但即使如此,Nanite描述的公式依旧生效,出现projected parent error < projected cluster error的情况时,该LOD级别被剔除,我们直接使用下一级别的LOD即可。
此时能确保LOD的position是无缝切换,但是无法让法线和光照也无缝切换(仅考虑了位置相关的Error)

上图中左侧为Unlit BaseColor,右侧为法线光照,可以发现左侧可以无缝切换,但是右侧光照明显突变。
幸运的是MeshOptimizer也支持属性权重的LOD简化(meshopt_simplifyWithAttributes),将UV/法线/切线的w分量也加入到网格的简化考虑因素中可以大大减少这种问题:
constexpr uint32 kAttributeCount = 9;
static const float attributeWeights[kAttributeCount] =
{
0.05f, 0.05f, // uv
0.5f, 0.5f, 0.5f, // normal
0.001f, 0.001f, 0.001f, 0.05f // tangent, .w is sign, weight bigger.
};
meshopt_simplifyWithAttributes(...attributeWeights);
BVH加速遍历
Nanite这种DAG组织形式,导致切出来的Cluster非常多,如何快速遍历也是一个问题。Nanite提出使用BVH来加速遍历。
根据前面的描述,如果一个Cluster Group,若它的Projected Parent Error <= 一个像素,那么则可以将其剔除。
把前面切出来的所有的Cluster Group Parent Error小球都放在世界空间中,构建BVH树。
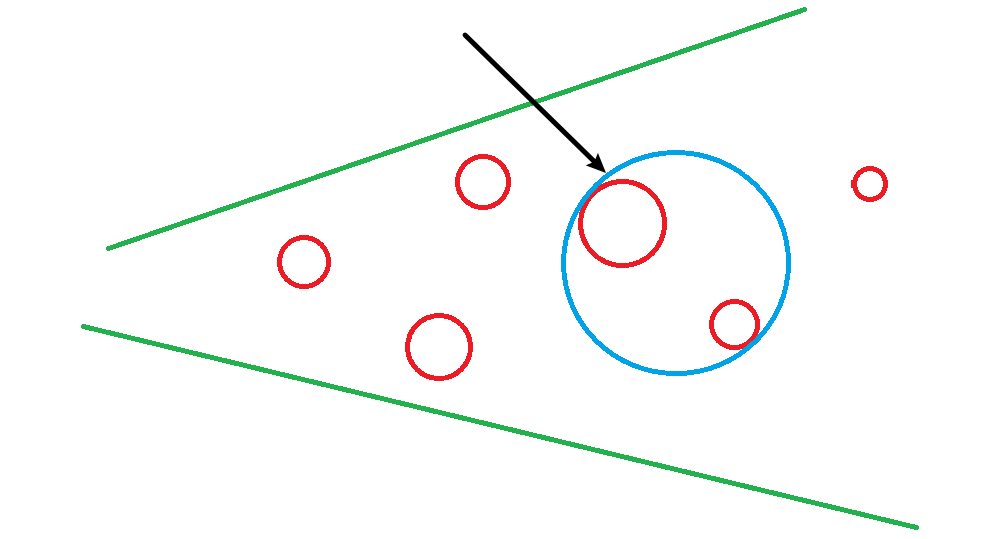
如上图所示,(蓝色球)父节点的Sphere Projected永远都比它的子节点(蓝色球内的红色球)的Sphere Projected半径要大,所以若父节点的Projected Sphere Radius <= 一个像素,那么子节点的Parent Error是必定小于一个像素的,可以直接剔除。
但比起直接遍历全部的Cluster Group,在GPU上遍历一颗BVH属实怎么写都很慢。
Nanite使用一种Persistent Thread + Parallel Queue的GPU编程技巧来均衡BVH的遍历性能:申请足够多的线程,在一次大循环中不停的检视BVH Node和做Cluster可见性剔除,这里大概分享下我的实现思路。(原始实现)
globallycoherent RWStructuredBuffer<int> rwBVHUncheckedNodeCount; // 待检查的BVH节点数
// 待消费的BVH Noded队列,不可用的Node用~0填充,.x为object id, .y为bvh node id.
globallycoherent RWStructuredBuffer<uint2> rwNode;
globallycoherent RWStructuredBuffer<int> rwProduce;
// Instance Culling会填充RootNode, rwProduce
// 已经消费的BVH Node数目,默认为0
globallycoherent RWStructuredBuffer<int> rwConsume;
[64, 1, 1]
void main()
{
uint bvhNodeCountNeedCheck;
uint consumeBVHNodeId = ~0;
while (true)
{
uint objectId = ~0;
uint nodeId = ~0;
// 检查中断条件
InterlockedMax(rwBVHUncheckedNodeCount, 0, bvhNodeCountNeedCheck);
bool bAllBVHNodeChecked = (bvhNodeCountNeedCheck == 0);
if (bAllBVHNodeChecked) { break; }
if (consumeBVHNodeId == ~0)
{
InterlockedAdd(rwConsume, 1, consumeBVHNodeId);
}
if (consumeBVHNodeId < kMaxNodeCount)
{
uint2 cmd = ~0;
InterlockedExchange(rwNode[consumeBVHNodeId].x, ~0, cmd.x);
InterlockedExchange(rwNode[consumeBVHNodeId].y, ~0, cmd.y);
if (any(cmd != ~0))
{
// 自旋直到当前节点全部信息可用
while (cmd.x == ~0)
{ InterlockedExchange(rwNode[consumeBVHNodeId].x, ~0, cmd.x); }
while (cmd.y == ~0)
{ InterlockedExchange(rwNode[consumeBVHNodeId].y, ~0, cmd.y); }
objectId = cmd.x;
nodeId = cmd.y;
// 当前节点被消费,重置便于下次循环再次申请。
consumeBVHNodeId = ~0;
}
}
if (objectId != ~0 && nodeId != ~0)
{
node = load(objectid, nodeid);
bool bVisibile = culled(node);
// 若不可见直接拒绝全部子节点
InterlockedAdd(rwBVHUncheckedNodeCount, bVisibile ? -1 : -node.bvhNodeCount);
if (bVisibile)
{
for (child : node.children)
{
// 生成新的节点供其他线程消费
InterlockedAdd(rwProduce, 1, i);
InterlockedExchange(rwNode[i].x, child.objectId);
InterlockedExchange(rwNode[i].y, child.nodeId);
}
for (meshletGroup : node.meshletGroups)
{
// 剔除和存储node里的meshletGroups.
}
}
}
else
{
// 空载...
}
}
}
这里需要小心使用各种原子操作,不然很容易就会死锁。
优化性能
(版本一)
均衡每个BVH子节点数目,默认每个父节点有8个子节点。
一个线程组中仅在第一个线程做Consume操作。如下图为例:第一次仅 Thread #0 有BVH Node需要计算:

若其可见,则生产出8个子节点,我们存到GroupShared内存里,下次循环中分配给8个线程:

再次可见的子节点最多生产出64个,正好占满全部的线程:

此时,如果再次可见的子节点溢出64个,才需要写入到Device内存中,让其它空转的线程组也发动起来。
这样能减少大量的原子操作和Device内存通讯,增加不少性能。
(版本二)
此时仍会有负载不均衡的情况,在没有BVH Node消费时,线程在空转。
增加一个Meshlet Culling的队列,我们不会在Node遍历时做计算繁重的Meshlet剔除,而是直接放到Device内存里让其它空转的线程来消费:
// 待消费的Meshlet队列,默认~0填充,.x为object id, .y为meshlet id.
globallycoherent RWStructuredBuffer<uint2> rwNode;
globallycoherent RWStructuredBuffer<int> rwProduce;
globallycoherent RWStructuredBuffer<int> rwConsume;
// ...
if (objectId != ~0 && nodeId != ~0)
{
if (bVisibile)
{
// ...
for (meshletGroup : node.meshletGroups)
{
// 生成新的Meshlet供其他线程消费
InterlockedAdd(rwProduce, 1, i);
InterlockedExchange(rwNode[i].x, meshletGroup.objectId);
InterlockedExchange(rwNode[i].y, meshletGroup.meshletid);
}
}
}
else
{
// 消费Meshlet Node并做剔除计算。
InterlockedAdd(rwConsume, 1, consumeMeshletId);
// Load and compute visibility...
}
基本消除了大部分空载。
这里可以用一些Wave指令来减少原子操作,比如仅在第一个Lane做消费操作,再把id广播到其它Lane。
虽然做了这么多操作,但性能说实话一般233(Bistro场景,3070Ti):

两次HZB剔除
与传统的HZB剔除(延迟一帧回读可见性)不同,第一次使用Prev HZB做剔除时,一定要用上一帧的MVP矩阵:

这样可以避免相机靠近物体时,Prev HZB无法挡住不断变大的物体,Stage#0额外多画了一些不必要的网格。
Tips#0: HZB构建使用AMD SPD相同的技巧,在一次Pass中完成全部级别的Mip。
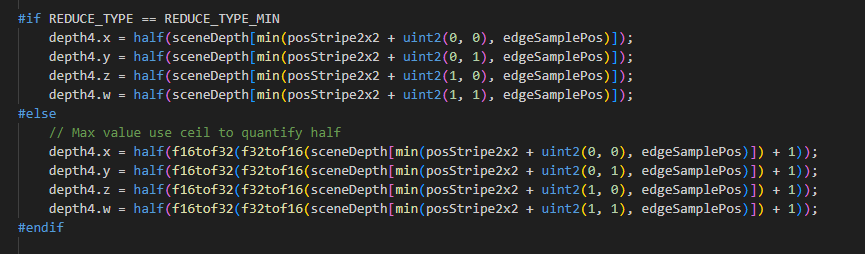
Tips#1: 如果没有使用Invert Z,并且HZB的格式是16Bit的,需要手动对32Bit的深度做Ceil,才能保证结果正确:
Visbility Buffer
与Nanite相同,使用Mesh Shader做Visibility Buffer生成,这样可以减少不必要的Buffer Write/Store,同时也不用维护一个未知大小的Index Buffer和Vertex Buffer。
在Mesh Shader中可以做一些三角形级别的剔除:
Back face剔除:
// Olano97: Triangle Scan Conversion using 2D Homogeneous Coordinates
bCulled = determinant(float3x3(positionHS_0.xyw, positionHS_1.xyw, positionHS_2.xyw)) <= 0;
Near plane剔除:
bCulled = (positionHS_0.w <= 0 && positionHS_1.w<= 0 && positionHS_2.w <= 0);
视锥剔除:
// Now cast to screen space.
const float2 uv_0 = positionHS_0.xy / abs(positionHS_0.w) * float2(0.5, -0.5) + 0.5;
const float2 uv_1 = positionHS_1.xy / abs(positionHS_1.w) * float2(0.5, -0.5) + 0.5;
const float2 uv_2 = positionHS_2.xy / abs(positionHS_2.w) * float2(0.5, -0.5) + 0.5;
const float2 maxUv = max(uv_0, max(uv_1, uv_2));
const float2 minUv = min(uv_0, min(uv_1, uv_2));
if (!bCulled)
{
bCulled = any(minUv >= 1) || any(maxUv <= 0);
}
小三角形剔除(没有位于任意一个着色中心点):
if (!bCulled)
{
const float2 maxScreenPosition = maxUv * perView.renderDimension.xy;
const float2 minScreenPosition = minUv * perView.renderDimension.xy;
bCulled = any(round(minScreenPosition) == round(maxScreenPosition));
}
Visibility Buffer仅需存储 8Bit的三角形Id, 24 Bit的ClusterId,共计花费32Bit。
Material Pass (Emit GBuffer)
按照8x8大小划分材质Tile,逐材质注入GBuffer。
使用变体隔开不同的材质,每个材质一次Dispatch,这样能最大化计算时的UAV Overlap。
由于仅存储了VisibilityBuffer,此时需要重新加载三角形计算其重心坐标与偏导数,手动插值:
struct Barycentrics
{
float3 interpolation;
float3 ddx;
float3 ddy;
};
// From Unreal Engine 5 Nanite.
// Improved perspective correct barycentric coordinates and partial derivatives using screen derivatives.
Barycentrics calculateTriangleBarycentrics(
float2 PixelClip,
float4 PointClip0,
float4 PointClip1,
float4 PointClip2,
float2 ViewInvSize)
{
Barycentrics barycentrics;
const float3 RcpW = rcp(float3(PointClip0.w, PointClip1.w, PointClip2.w));
const float3 Pos0 = PointClip0.xyz * RcpW.x;
const float3 Pos1 = PointClip1.xyz * RcpW.y;
const float3 Pos2 = PointClip2.xyz * RcpW.z;
const float3 Pos120X = float3(Pos1.x, Pos2.x, Pos0.x);
const float3 Pos120Y = float3(Pos1.y, Pos2.y, Pos0.y);
const float3 Pos201X = float3(Pos2.x, Pos0.x, Pos1.x);
const float3 Pos201Y = float3(Pos2.y, Pos0.y, Pos1.y);
const float3 C_dx = Pos201Y - Pos120Y;
const float3 C_dy = Pos120X - Pos201X;
const float3 C = C_dx * (PixelClip.x - Pos120X) + C_dy * (PixelClip.y - Pos120Y);
const float3 G = C * RcpW;
const float H = dot(C, RcpW);
const float RcpH = rcp(H);
barycentrics.interpolation = G * RcpH;
const float3 G_dx = C_dx * RcpW;
const float3 G_dy = C_dy * RcpW;
const float H_dx = dot(C_dx, RcpW);
const float H_dy = dot(C_dy, RcpW);
barycentrics.ddx = (G_dx * H - G * H_dx) * (RcpH * RcpH) * ( 2.0f * ViewInvSize.x);
barycentrics.ddy = (G_dy * H - G * H_dy) * (RcpH * RcpH) * (-2.0f * ViewInvSize.y);
return barycentrics;
}
// Usage:
/*
float2 meshUv =
triangleInfo.uv[0] * barycentric.x +
triangleInfo.uv[1] * barycentric.y +
triangleInfo.uv[2] * barycentric.z;
float2 meshUv_ddx =
triangleInfo.uv[0] * ddx.x +
triangleInfo.uv[1] * ddx.y +
triangleInfo.uv[2] * ddx.z;
float2 meshUv_ddy =
triangleInfo.uv[0] * ddy.x +
triangleInfo.uv[1] * ddy.y +
triangleInfo.uv[2] * ddy.z;
baseColor = texture.SampleGrad(sampler, meshUv, meshUv_ddx, meshUv_ddy);
*/
优化性能
可视化场景中的三角形:

一种直观的想法是:
有些Wave内使用同一个三角形,因此,加载三角形时是否可以复用其它Lane的三角形信息,减少带宽消耗?
TriangleMiscInfo triangleInfo;
#if ENABLE_WAVE_LOCAL_SHUFFLE
const uint currentLaneIndex = WaveGetLaneIndex();
uint targetLaneIndex;
uint activeMask = WaveActiveBallot(true).x;
while (activeMask != 0)
{
targetLaneIndex = firstbitlow(activeMask);
if (targetLaneIndex >= currentLaneIndex)
{
break; // Reach edge.
}
// WaveReadLaneAt in loop never work.
const uint targetPackId = sharedPackId[sharedIdOffset + targetLaneIndex];
if (targetPackId == packId)
{
break; // Found reuse.
}
// Step next.
activeMask ^= (1U << targetLaneIndex);
}
[branch]
if (currentLaneIndex == targetLaneIndex)
{
// Only Active lane load triangle info.
getTriangleMiscInfo(...);
}
[unroll(3)]
for (uint i = 0; i < 3; i ++)
{
triangleInfo.uv[i] = WaveReadLaneAt(triangleInfo.uv[i], targetLaneIndex);
triangleInfo.p[i] = WaveReadLaneAt(triangleInfo.p[i], targetLaneIndex);
triangleInfo.t[i] = WaveReadLaneAt(triangleInfo.t[i], targetLaneIndex);
triangleInfo.bi[i] = WaveReadLaneAt(triangleInfo.bi[i], targetLaneIndex);
triangleInfo.n[i] = WaveReadLaneAt(triangleInfo.n[i], targetLaneIndex);
}
#else
getTriangleMiscInfo(...);
#endif
用红色代表加载并计算三角形的Lane,绿色代表复用的Lane,可视化如下:

大部分像素都是可复用优化的。此时统计性能比较(Bistro ~4k 3070Ti):
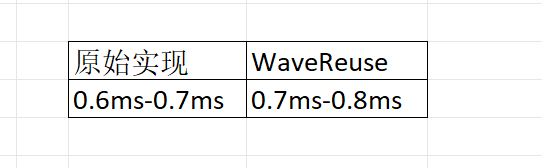
性能反而更慢了。
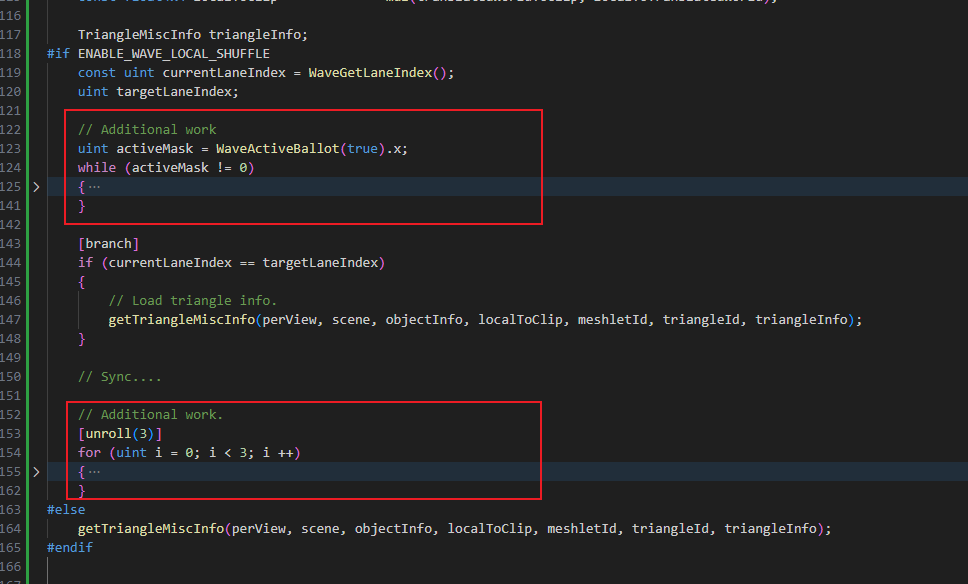
虽然用branch选择性的加载三角形减少了整体的带宽消耗,但Wave整体执行速度取决于最慢的Lane什么时候完成三角形加载,在增加了Reuse后,最慢的Lane原本的任务并没有减少,还多了一些Additional Work。
另外一种想法是:
一条线程处理屏幕上连续的2x2像素的任务,缓存三角形信息,仅在需要加载的时候才加载三角形:
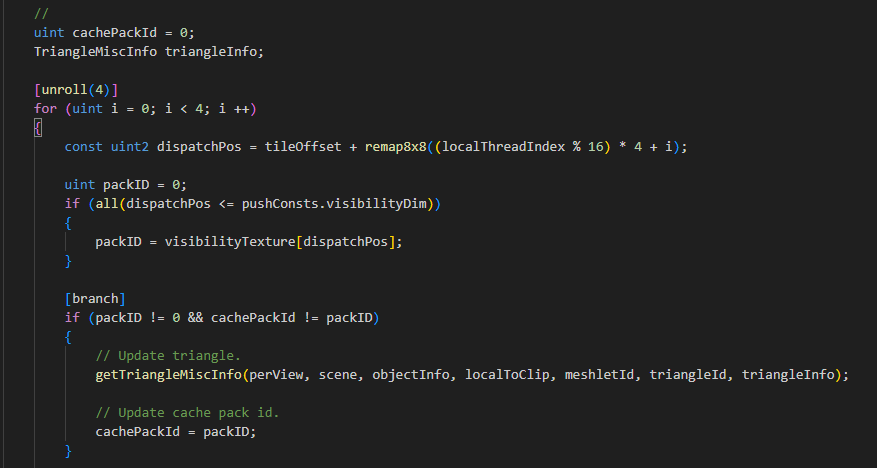
这样做有个好处是每条Lane都大概率能复用2-3次三角形,综合到Wave最好情况能在2x2像素内仅加载一次三角形。
除此之外,还可以在lane需要加载三角形时从WaveFirstActiveLane抽奖:
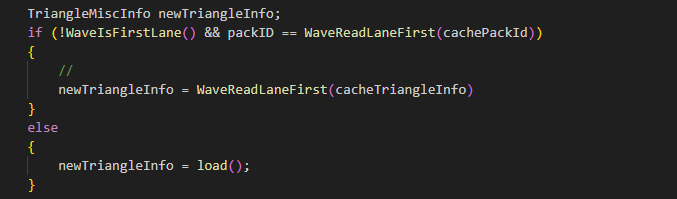
可视化每条线程的三角形加载数目如下:大部分线程在2x2范围内仅加载一次三角形。

性能(Bistro ~4k 3070Ti):

最终效果
无缝LOD过渡:

Meshlet LOD过渡可视化:

三角形过渡可视化:
