Vulkan异步队列与异步纹理上传
Vulkan 常用的队列族有以下四种:
- VK_QUEUE_GRAPHICS_BIT 图形队列族
- VK_QUEUE_COMPUTE_BIT 计算队列族
- VK_QUEUE_TRANSFER_BIT 传输队列族
- VK_QUEUE_SPARSE_BINDING_BIT 稀疏绑定队列族
基本上,现在机器的图形卡基本都含有(1、2、3)这些独立的队列族,(4 稀疏绑定貌似在RTX显卡上才有)。
可以通过以下Api查询图形卡的队列族的支持信息:
VKAPI_ATTR void VKAPI_CALL vkGetPhysicalDeviceQueueFamilyProperties(
VkPhysicalDevice physicalDevice,
uint32_t* pQueueFamilyPropertyCount,
VkQueueFamilyProperties* pQueueFamilyProperties);
得到VkQueueFamilyProperties后,可以使用queueFlags标记来判断队列族的支持情况:
if (queueFamily.queueFlags & VK_QUEUE_GRAPHICS_BIT)
{
// 图形队列族
}
else if (queueFamily.queueFlags & VK_QUEUE_COMPUTE_BIT)
{
// 具有单独的计算队列族
}
else if(queueFamily.queueFlags & VK_QUEUE_TRANSFER_BIT)
{
// 具有单独的传输队列族
}
而异步上传或异步计算,关键就是判断显卡是否含有单独的传输队列族或计算队列族。
我首先获取到队列族信息,在创建Vulkan Logic Device时,可以根据每个队列族的最大支持情况申请对应的队列。
在我的引擎中,我共申请了三个主队列:Graphics、Compute、Present:
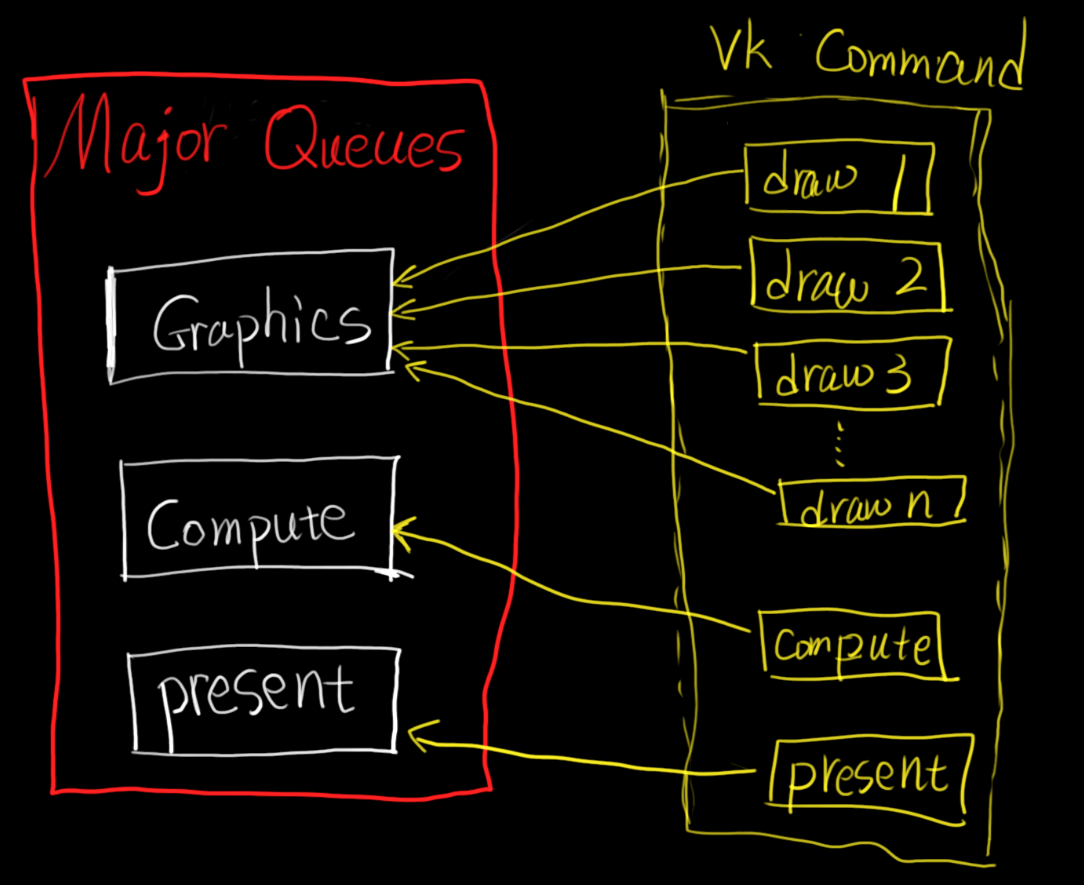
在绘制一帧的过程中:
记录着图形绘制命令(VkCmdDraw*)的CommandBuffer都会提交到Graphics队列中。
记录着异步计算命令(vkCmdDispatch)的CommandBuffer都会提交到计算队列中。
显示命令(vkQueuePresentKHR)则使用Present队列。
这三个主队列是每帧图形绘制专用的,它们仅关心和接受当前帧的图形计算与显示。
异步队列
当引擎运行时,可能会有一些异步的图形操作,比如,运行时加载很多纹理、运行时计算LUT图并序列化。对于这些图形请求,比较简单的做法是在当前帧的处理阶段插入一个提交一次的CommandBuffer,提交它到图形队列中并且阻塞等待它运行完成:
inline void executeImmediately(...)
{
auto cmdBuf = commandPool.allocate();
record(cmdBuf);
// 提交队列
vkQueueSubmit(queue, 1, &submitInfo, VK_NULL_HANDLE);
// 等待队列
vkQueueWaitIdle(queue);
free(cmdBuf);
}
问题在于vkQueueWaitIdle会阻塞主线程很长一段时间,在这段时间内帧率下降得非常严重!
一个Navie的缓解方法是把所有的加载任务切割到多帧加载,比如,一共有1000张纹理要加载,按照切割任务,我们可以划分到每帧加载100张纹理,这样,主线程的阻塞时间也会相应的减少。
void Tick()
{
constexpr auto perTickLoadNum = 100;
for(auto i = 0; i < perTickLoadNum; i++)
{
// ...
loadTexture2DImage(textureContainer[i]);
}
}
但这里阻塞还是非常严重,Benchmark显示一半的时间都在vkQueueWaitIdle上了。
增加异步队列
在创建LogicDevice时,我直接按照每种队列族支持的最大数目队列来创建,并把除了主队列外的空余队列存入available*Queues容器中:
class VulkanDevice
{
public:
VkQueue graphicsQueue = VK_NULL_HANDLE; // 主图形队列
VkQueue presentQueue = VK_NULL_HANDLE; // 主显示队列
VkQueue computeQueue = VK_NULL_HANDLE; // 主计算队列(用于辅助主图形队列的异步计算)
// 剩余的队列
std::vector<VkQueue> availableTransferQueues; // 所有可用的传输队列
std::vector<VkQueue> availableComputeQueues; // 所有可用的计算队列
std::vector<VkQueue> availableGraphicsQueues; // 所有可用的图形队列
};
此时,纹理上传将不再经过graphicsQueue,而是使用availableTransferQueues中的队列。
并且,由于使用了单独的队列,每个纹理的加载上传可以放在一个单独的线程中进行。
同步
纹理上传的命令提交到availableTransferQueues中时,需要使用一个VkFence来指示命令的执行情况。
由于引擎中纹理上传命令很多,如果我们每次都手动创建销毁VkFence,也会产生不小的开销,我们需要用一个池来管理重用这些Fence:
class VulkanFencePool
{
public:
std::vector<VulkanFence*> m_freeFences;
std::vector<VulkanFence*> m_busyFences;
VkResult checkFenceState(VulkanFence* fence)
{
return vkGetFenceStatus(m_device, fence->m_fence);
}
VulkanFence* createFence(bool signaledOnCreate)
{
if (m_freeFences.size() > 0)
{
Ref<VulkanFence> fence = m_freeFences.back();
m_freeFences.pop_back();
m_busyFences.push_back(fence);
if (signaledOnCreate)
{
fence->m_state = VulkanFence::State::Signaled;
}
return fence;
}
VulkanFence* newFence = new VulkanFence(m_device, this, signaledOnCreate);
m_busyFences.push_back(newFence);
return newFence;
}
void releaseFence(VulkanFence*& fence)
{
resetFence(fence);
for (int32 i = 0; i < m_busyFences.size(); ++i)
{
if (m_busyFences[i] == fence)
{
m_busyFences.erase(m_busyFences.begin() + i);
break;
}
}
m_freeFences.push_back(fence);
fence = nullptr;
}
};
我们将使用后的Fence放入到m_freeFences中,在下次需要新的Fence时直接从里面取即可。
判断当前提交的命令是否执行完毕的核心函数是vkGetFenceStatus,它返回了Fence的信号状态。
由于Vulkan不帮我们保存异步执行的状态信息,我们需要手动存储当前异步命令用到的一些临时信息如CommandBuffer、VulkanBuffer等,直到VkFence明确发出完成的信号了才能销毁。
最简单的办法就是封装一个Task结构体:
struct GpuUploadTextureAsync
{
bool m_ready = false;
VkCommandPool m_pool = VK_NULL_HANDLE;
VkDevice m_device = VK_NULL_HANDLE;
VkQueue m_queue = VK_NULL_HANDLE;
Ref<VulkanFence> fence = nullptr;
std::vector<VulkanBuffer*> uploadBuffers{};
std::function<void()> finishCallBack{};
VkCommandBuffer cmdBuf = VK_NULL_HANDLE;
void release()
{
if(fence!=nullptr)
{
VulkanRHI::get()->getFencePool().waitAndReleaseFence(fence,1000000);
fence = nullptr;
}
if(uploadBuffers.size()>0)
{
for(auto* buf : uploadBuffers)
{
delete buf;
buf = nullptr;
}
uploadBuffers.clear();
uploadBuffers.resize(0);
}
finishCallBack = {};
if(cmdBuf!=VK_NULL_HANDLE)
{
vkFreeCommandBuffers(m_device,m_pool,1,&cmdBuf);
cmdBuf = VK_NULL_HANDLE;
}
}
// NOTE: Call every frame.
bool tick()
{
if(!m_ready)
{
if(VulkanRHI::get()->getFencePool().isFenceSignaled(fence))
{
m_ready = true;
if(finishCallBack)
{
finishCallBack();
}
release();
}
}
return m_ready;
}
};
我们在该Task结构体中缓存了当前命令的所有数据,并且直到Fence明确发出完成信号后再释放!
Mipmaps
图片的Mipmaps上传是一个很麻烦的事情。
首先我们排除运行时生成mipmap的做法(非常慢,而且耗费GPU资源(计算资源或图形资源))。
在我的引擎中,会对图片原始资源做预处理,包括mipmap生成、srgb标记等,然后将这些数据缓存到连续的二进制文件中。
离线生成mipmap并加载的方式缺点在于内存碎片过多。在Vulkan的Api设计中,没有直接对全部mipmap一起填充内存的api,必须对每一级mipmap单独来一次copy,像这样:
VKAPI_ATTR void VKAPI_CALL vkCmdCopyBufferToImage(
VkCommandBuffer commandBuffer,
VkBuffer srcBuffer, // 没有Buffer Offset可用!
VkImage dstImage,
VkImageLayout dstImageLayout,
uint32_t regionCount,
const VkBufferImageCopy* pRegions);
for(uint32 level = 0; level<info.mipmapLevels; level++)
{
CHECK(mipWidth >= 1 && mipHeight >= 1);
uint32 currentMipLevelSize = mipWidth * mipHeight * TEXTURE_COMPONENT;
auto* stageBuffer = VulkanBuffer::create(
// ...
(VkDeviceSize)currentMipLevelSize,
(void*)(pixelData.data() + offsetPtr)
);
uploader->uploadBuffers.push_back(stageBuffer);
mipWidth /= 2;
mipHeight /= 2;
offsetPtr += currentMipLevelSize;
}
问题在于,一张2k的纹理,mipmap级别可能有11级,这样stageBuffer就得创建11次,这还不算最大的问题,严重的问题在于,在高级mipmap中,像素数据量基本是1x1、2x2、4x4这种级别,这种小数据碎片化特别严重,并且由于独显的Copy带宽一般很充裕,这就导致了256x256级别的StageBuffer和1x1、2x2、4x4这种小级别的StageBuffer花费基本相同的上传时间。
性能对比
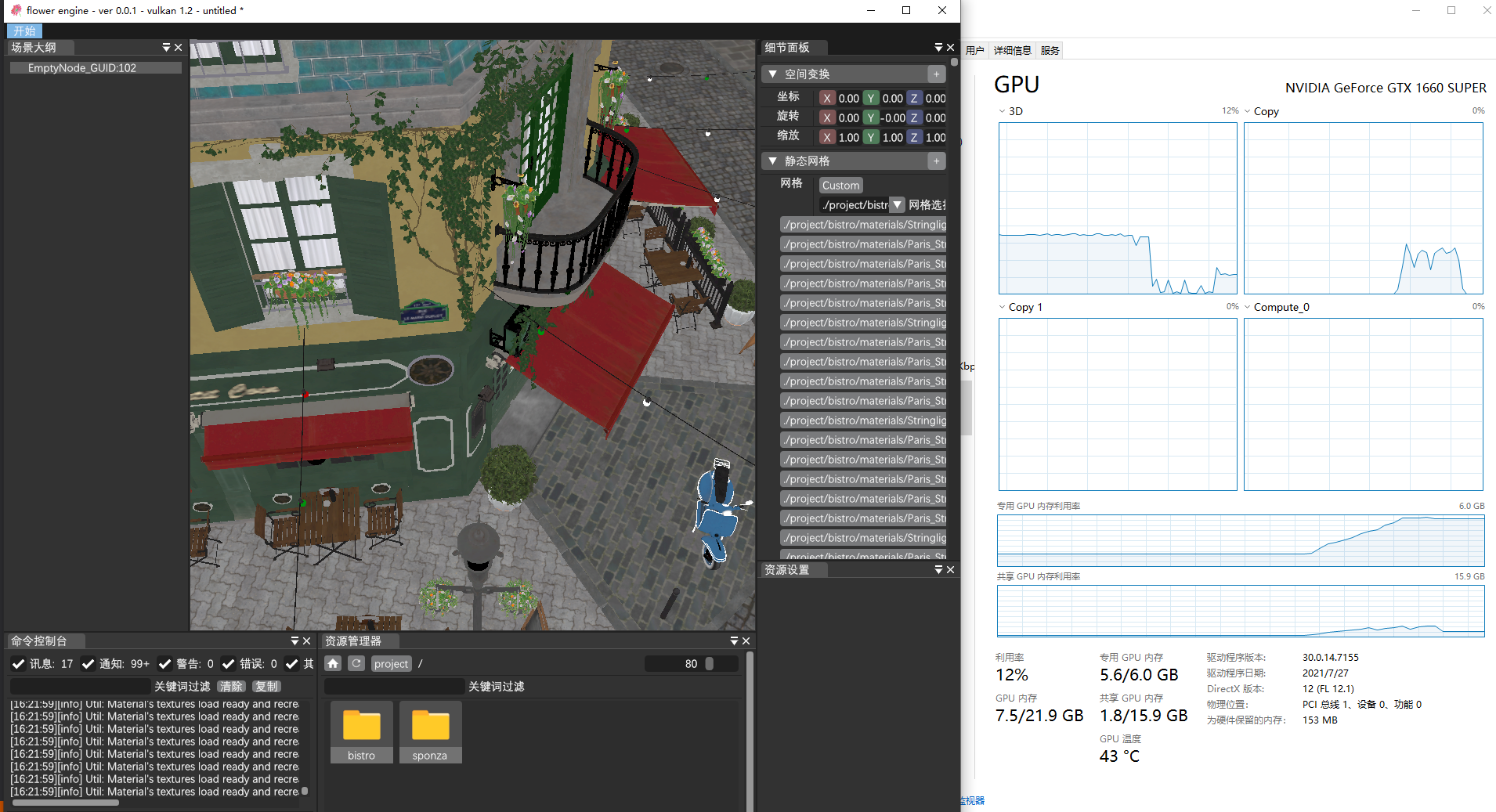
用Bistro场景做比较,我们一次性上传633张4k纹理(共1.8G)。
阻塞式:Runtime GenerateMipmap ~ 4min 0Fps
阻塞式:Offline ~ 2min 0Fps
切片式(10张/帧):Runtime GenerateMipmap ~ 6min 2Fps
异步切片式 (100张/帧):Offline ~10s 10Fps
如下所示为异步加载时的3D(Graphics)和Copy队列的运行占用情况: