简单实现UE5中的VirtualShadowMap与性能对比
在2021年UE5的Siggraph大会上,Epic的PPT简略提到了VirtualShadowMap的实现原理,但还是看得一脸懵逼。
新台式电脑到货后,重新下载了UE5开始调试,初略了解了VSM的运行原理,在最近一个月来都在引擎中实现Directional Light的Virtual Shadow Map, 这里分享一下具体原理与实现细节。
常规的ShadowMap算法中,先从灯光方向得到一张ShadowMap。
如果Shadowmap分辨率过低,极易出现阴影锯齿。缓解锯齿的方法是增加ShadowMap的分辨率,比如ShadowMap分辨率提高到16k * 16k。

问题在于我们没有这么多显存可用。因此没办法直接申请这么大的ShadowMap。
假设存在一张虚拟的16k*16k巨大shadowmap,首先把它划分为块,称为Virtual Tile:
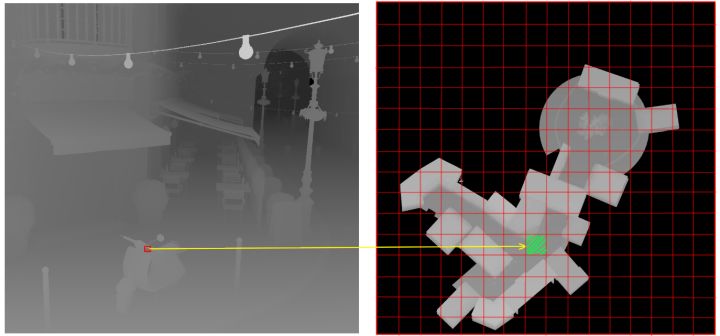
渲染完Depth pass后,我们有当前帧的深度,从深度重建世界空间位置后,再投影到灯光的视口下,转化为NDC空间坐标后。很简单就能得出当前像素位于哪块Virtual Tile上。
如下图所示,左边红色像素转化为灯光视口下后对于右边的绿色部分Virtual Tile,我们标记这部分的Virtual Tile设为Used。
当前帧每个像素深度都转化一次,得到所有的Used Virtual Tiled(标为绿色的Virtual Tile):
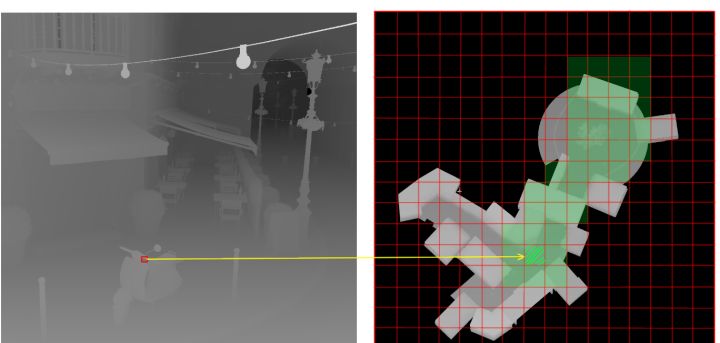
由于我们只需要渲染当前屏幕中每个像素阴影,所以,对于一张16k*16k的shadowmap,我们仅会用到标绿的Used Virtual Tile,其余的Virtual Tile都是不需要用到的。
于是,我们只需要渲染使用到的Virtual Tile的深度就行了。
为了盛放这些Used Virtual Tile数据,我们申请一张支持UAV读写的RenderTarget,称为Physical Image,然后把Used Virtual Tile整整齐齐的放到这个Physical Image里面,这个步骤称为Tile Padding,其中,Physical Image划分的Tile称为Physical Tile,并且,保证Virtual Tile的尺寸和Physical Tile相同。
渲染ShadowMap深度时,我们使用和Physical Tile大小相等的光栅化视口,关闭深度比较,传入Physical Image的UAV View,在pixel shader中判断当前片元该往哪块Physical Tile写入深度,并使用Atmoic Compare操作实现深度测试和写入。
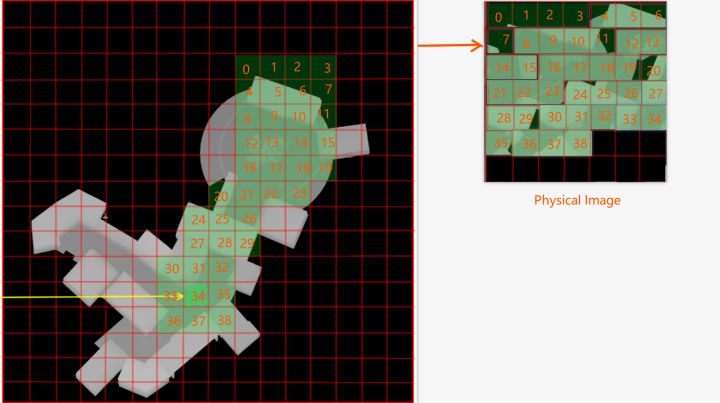
Lighting部分计算阴影时,只需判断当前深度位于哪块Virtual Tile上,再转化为Physical Tile的位置,然后从Physical Image中读光源深度,接下来走正常shadowmap lighting流程即可。
如果场景非常大,单张Virtual Shadow Map实际上是满足不了精度需求的。
于是UE5使用Mipmap作为适配,以1 screen pixel 对应 1 shadowmap texel作为标准计算Mipmap的Level。
首先是Mipmap适配的原理:
如下图所示,红点为当前相机的世界位置,最高一级mip0的投影范围最小,每个virtual tile的shadowmap精度最高,此后每一级mip覆盖的面积都是原来的2 * 2倍。
Mipmap类型的Virtual shadowmap流程与单级Virtual Shadow map类似,不过多了一个Mipmap Level的计算。首先根据深度算出当前屏幕对应的Mipmap Level级别。然后再到对应的Virtual Shadow Map中标记对应的Tile是否为Used。Tile Padding时,由于每一级Mipmap的Virtual Shadow Map Tile大小是一样的,所以是可以Padding到一张Physical Image中的。
接下来是Mipmap的Level的计算公式。
公式相同于屏幕空间纹理的mipmap level计算公式。根据当前帧的屏幕深度我们可以计算出当前屏幕像素到相机的距离,首先消除fov对xy方向的缩放,接下来使用log公式计算z方向的lod bias,具体代码如下:
float getClipmapLODBasicBias(in const mat4 projectMatrix, in const vec2 screenResolution)
{
// we expected 1 pixel on screen match 1 texel on shadow map.
// we keep a virtual 16k * 16k shadow map.
// and our screen maybe just 2k or 4k resolution.
// so add a basic lod bias to avoid waste.
// fov scale on xy.
const float xScale = abs(projectMatrix[0][0]);
const float yScale = abs(projectMatrix[1][1]);
const vec2 renderScreenSize = screenResolution * vec2(xScale, yScale);
const float maxEdgeSize = max(renderScreenSize.x, renderScreenSize.y);
const float basicClipMapResolution = VIRTUAL_CLIP_MAP_PAGE_DIM_XY * VIRTUAL_PAGE_SiZE;
const float basicScale = basicClipMapResolution / maxEdgeSize;
// high quality.
const float lodBias = -1.0f;
// basicScale * 2.0f to add some space for lodBias, for more easy to controling.
return max(0.0f, lodBias + log2(basicScale * 2.0f));
}
这个1 screen pixel 对应 1 shadow map texel只能是某种程度上的对应,太阳接近地平线时,拉长的阴影分辨率非常的低,效果并不好。
对这个问题,UE5的建议是减少LOD bias,这回导致Mipmap0覆盖的Used Tile数会非常的多,最后Physical Tiled数目也会增加。
我的做法是太阳接近地平线时切换回Sample distribution shadow map方法,增加了一个Shadow Edge的Mask,并在切换途中降低Mask区域TAA的Blend Factor实现柔和渐变。
简单原理基本就只有这些,接下来说明一下在实现中的Pipeline详细。
Virtual Shadow Map需要配合Gpu Batch流程,UE5中使用庞大的Nanite实现三角形级别的Gpu Batch,我这里仅是实现了Per object的Batch流程,实现的光源类型是Directional Light,使用的图形Api是Vulkan1.2,相关渲染管线如下:
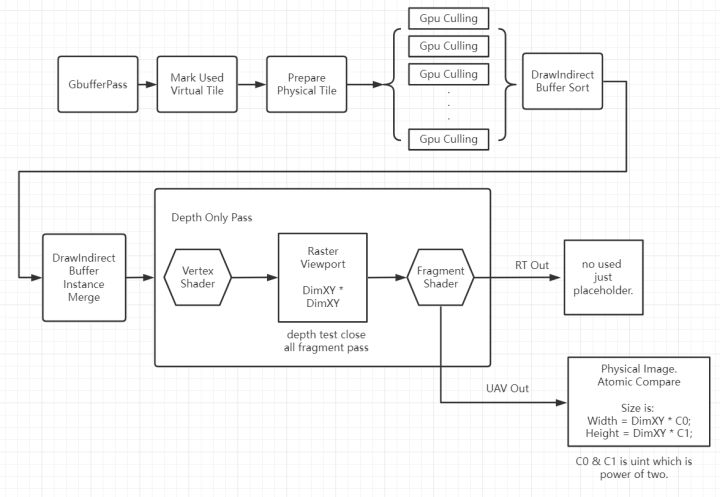
首先设每一级Virtual ShadowMap的Tile数为VIRTUAL_CLIP_MAP_PAGE_DIM_XY, 设有VIRTUAL_CLIPMAP_COUNT个Mimap。
在Gbuffer Pass后,传入的DepthStencil用于计算每一级Mipmap Virtual ShadowMap的Used Tile情况,这个Pass我称为MarkUsedVirtualTilePass.
这个Pass的步骤很简单,申请每一级Virtual Shadow Map的Virtual Tile Flag数组,判断屏幕中深度落入到这个Tile时,把它Mark为true即可。
简单的判断逻辑如下:
// screen space.
void main()
{
// ...
vec3 worldPos = posWorldRebuild.xyz / posWorldRebuild.w;
float basicLODOffset = getClipmapLODBasicBias(viewData.camProj, vec2(textureSize(inDepth,0)));
// first get world clipmap level, then get page location.
float viewToWorldDistance = length(worldPos - viewData.camWorldPos.xyz) * VIRTUAL_DISTANCE_UNIT_SCALE;
float log2Distance = log2(viewToWorldDistance);
int absoluteClipmapLevel = int(floor(log2Distance + basicLODOffset));
int relativeClipmapLevel = max(absoluteClipmapLevel - VIRTUAL_CLIPMAP_MIN_LEVEL, 0);
if(relativeClipmapLevel >= VIRTUAL_CLIPMAP_COUNT)
{
return;
}
vec4 shaodwProjectPos = viewData.clipMapViewProjectMatrix[relativeClipmapLevel] * vec4(worldPos, 1.0f);
shaodwProjectPos.xyz = shaodwProjectPos.xyz / shaodwProjectPos.w;
bool bShaodwInClip = shaodwProjectPos.w > 0.0f &&
(shaodwProjectPos.x >= -1.0f && shaodwProjectPos.x <= 1.0f) &&
(shaodwProjectPos.y >= -1.0f && shaodwProjectPos.y <= 1.0f) &&
(shaodwProjectPos.z >= 0.0f && shaodwProjectPos.x <= 1.0f);
if(!bShaodwInClip)
{
return;
}
float perPageDim = 1.0f / float(VIRTUAL_CLIP_MAP_PAGE_DIM_XY);
// remap [0, 1]
vec2 posXY = 0.5f * (shaodwProjectPos.xy + 1.0f);
int xDim = int(floor(posXY.x / perPageDim));
int yDim = int(floor(posXY.y / perPageDim)); // sometimes it is 125?
int flatPos = yDim * VIRTUAL_CLIP_MAP_PAGE_DIM_XY + xDim
+ relativeClipmapLevel * VIRTUAL_CLIP_MAP_PAGE_DIM_XY * VIRTUAL_CLIP_MAP_PAGE_DIM_XY;
// mark page pos.
flags[flatPos].flag = 1;
}
第二个Pass是PreparePhysicalTilePass,Dispatch一个VIRTUAL_CLIPMAP_COUNT * VIRTUAL_CLIP_MAP_PAGE_DIM_XY * VIRTUAL_CLIP_MAP_PAGE_DIM_XY大小的计算着色器,这样每个线程对应一个Virtual Tile,然后读取上一个Pass中的Virtual Tile Flag数组数据,如果标记为true,则Atomic Add得到当前Used Virtual Tile对应的Physical Tile的Id,然后把Id数据存到SSBO Buffer中,便于渲染深度时和Lighting计算阴影时可以直接得到对应的转换数据:
第三个Pass是GpuCulling,在第二个Pass结束后,我们实际上已经可以画shadow depth了,不过由于每个Tile都是一个视口,并且一个物体可能在多个Tile中渲染,常规做法非常慢,所以需要Gpu Culling和Instance Merge.
我的Culling仅做了常规的Per Tile Frustum Culling,得到一个IndexedIndirectCommand Buffer,其定义如下:
struct IndexedIndirectCommand
{
uint indexCount;
uint instanceCount;
uint firstIndex;
uint vertexOffset;
uint firstInstance;
uint objectId;
};
直接Culling后DrawIndexIndirect还是不够快,Nsight Profile显示Bounding是在VertexShader的Input Stream阶段,因此我做了一个DrawIndexIndirect Buffer Sort Pass, 按照 firstIndex + vertex Offset 做排序,使用排序后的buffer再绘制。
最后一个优化是instance优化,(不过在RTX显卡上似乎是负优化),在Sort Pass后,将 firstIndex 和vertex offset相同的command中instance count相加,然后再根据instance count做一次排序,刷新drawcount,然后使用instance merge的buffer和刷新后drawcount调用vkCmdDrawIndexedIndirectCount.
DepthOnlyPass和LightingPass根据PreparePhysicalTilePass得到的索引数据,去索引全局UniformBuffer中的VirtualTile中的ViewProjectionMatrix即可。
DepthOnlyPass Fragment深度写入阶段,使用AtomicComp操作往Physical Image对应的Tile 位置上写入信息,另外,GLSL不支持float类型的Atomic操作,所以先转化为Uint类型再写入。
表现比较
由于我没有做Virtual ShadowMap Cache,实际上测下来Virtual Shadowmap的效率是很捉急的,另外Culling阶段还可以用hiz进一步剔除。
光栅化阶段我是按照Tile大小光栅化,由于每个Tile只设了128*128,光栅化速度很慢,似乎可以用MultiView扩展加速,但我没用过MultiView功能所以没有弄。
但哪怕是这种没有优化过的VSM,效果都媲美 8级SDSM, 速度接近于 4级SDSM(Bistro场景)。
如下图所示,VSM Bias设为-1.0f, 得到清晰锐利的阴影边缘(没有任何filter)。

软阴影部分,我没有使用UE5的SMRT算法,而是使用固定大小的泊松盘采样,由于ShadowMap精度很高,所以我使用梯度噪声逐帧旋转泊松盘,配和TAA在4次采样内即可让软阴影收敛:
Hard Shadow Only:

Soft Shadow Only:

Composite:
