TextureCache Miss问题
之前做地形纹理拼接时遇到大量的Texture Cache Miss问题,导致着色程序的性能下降,正好周末有空可以看这个论文:http://fileadmin.cs.lth.se/cs/Personal/Michael_Doggett/pubs/doggett12-tc.pdf 。
论文Texture Cache的相关内容如下:
Gpu内部架构的简易示例图如下:
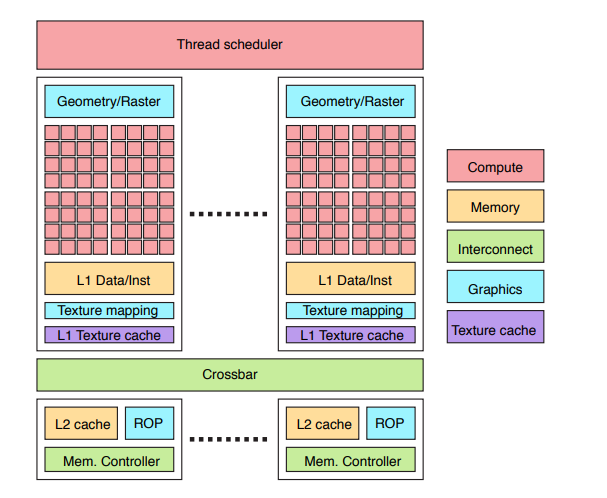
- Texture Cache物理位置在图形核心(Texture Mapping Graphics)处理器旁边,因此高吞吐低延迟,它是专门存储贴图纹理数据的一片只读Cache,上方有很多shader核心,它们共享下方的纹理单元(Texture units)。着色器执行纹理读取时,通过总线向纹理单元发送请求,此时Shader可能继续执行也可能被挂起等待返回的结果,这一步是异步的。而纹理单元处理请求,执行寻址操作(ddx(uv),ddy(uv)来选择mip级别, 执行滤波操作(如双向过滤的滤波,三向过滤的mipmap结果混合), 将uv转换为纹素坐标(uv*该级mipmap的长宽),clamp/wrap,etc),得到需要纹理数组的下标,之后在缓存层级中去查找。
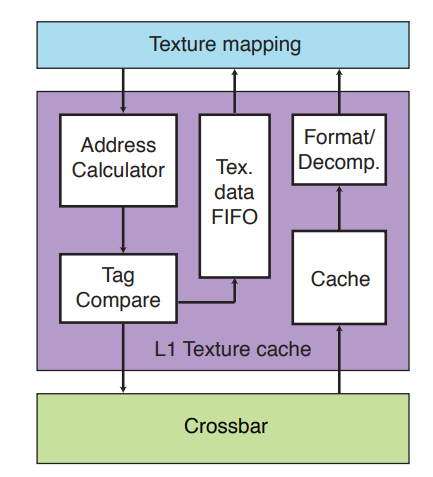
- Gpu的缓存层级类似于Cpu的高速缓存层级,也分为一级、二级等缓存,一级物理位置最接近Shader核心并且无需通过CrossBar传递,采样时,Gpu会一次加载当前位置临近的纹理数据进L1 Texture Cache中,如果每次采样都是按顺序采样或者采样临近位置的纹理数据,那么Cache中,Cache的命中率会非常的高,无需频繁从L2级Cache加载数据。
而那个拼接式的地形纹理因为每次都在片元着色器重新计算uv和mip级别,基本每次都没有命中Cache,Texture Cache Miss非常严重,导致采样贴图性能下降,虽然收益于带宽,但是最终也提高了每次采样纹理的代价。